
ในที่สุดก็มาถึงตอนที่จะแสดงพลังที่แท้จริงของ Python ในความคิดของผมซักที นั่นก็คือ การที่เราสามารถเรียกใช้ Code จาก Module/Packages ภาษา Python ที่มีคนเจ๋งๆ เขียนไว้มากมาย เพราะมันเป็นภาษาที่ได้รับความนิยมสูงมากนั่นเอง
ต้องเกริ่นนิดนึงว่าเราสามารถเขียนสร้าง function/class ภาษา Python แล้ว save เป็นไฟล์ .py แยกไว้เป็นอีกไฟล์นึงแล้วสามารถเรียกใช้คำสั่งในไฟล์นั้นจากโปรแกรม python ไฟล์อื่นๆ ได้ โดยสามารถเรียกใช้ผ่านคำสั่งที่ชื่อว่า import โดยไม่ต้องมานั่งเขียน code ใหม่นั่นแหละ (แต่ตอนนี้ผมยังไม่ได้อธิบายว่า class คืออะไรเนอะ เอาแบบคร่าวๆ คือมันเป็น object แบบนึงที่เราสร้างขึ้นมาได้เองละกัน)
พอทำแบบนี้ได้ คนเค้าก็เลยออกแบบโปรแกรมโดยแยกส่วนของโปรแกรมย่อยออกไปเป็นอีกส่วนจากโปรแกรมหลัก นั่นคือพยายามเขียนชุดคำสั่งที่อาจถูกเรียกใช้บ่อยๆ แยกไว้เป็นไฟล์ .py อีกอัน โดยจะเรียกว่า Module ซึ่งใน module หนึ่งๆ ก็มักจะรวม code คำสั่งเรื่องคล้ายๆ กันไว้ด้วยกัน
นอกจากนี้สามารถสร้าง module ได้หลายอัน (ไฟล์ .pyหลายไฟล์) แล้วจัดรวมเป็นกลุ่มที่เรียกว่า Package ได้อีกด้วย ซึ่งจะช่วยให้การทำงานเป็นระบบระเบียบมากขึ้น ไม่งงว่าตกลง module ไหนบ้างที่อยู่กลุ่มเดียวกัน
อย่างไรก็ตามผมจะไม่ได้มาพูดถึงการสร้าง Module หรือ Packages ด้วยตนเองในบทความนี้ แต่จะพูดถึงการเอา Module/Packages ของคนเก่งๆ คนอื่นที่เค้าแจกใน internet ซึ่งอยู่ในเว็บ pypi.org มาใช้ต่างหาก
สารบัญ
การ install Packages ด้วยคำสั่ง pip
ปกติแล้ว ถ้าจะ import module/packages ต่างๆ มาใช้งานได้นั้น เราต้องมีไฟล์ .py ต่างๆ ใน folder ที่เราใช้ทำงานก่อน แต่ถ้าเจ้า module/packages ที่เราต้องการมันยังอยู่ใน pypi.org อยู่เลย เราก็ต้อง install ไฟล์เหล่านั้นให้มาอยู่ใน ใน folder ที่เราใช้ทำงานก่อนนั่นเอง ซึ่งเราสามารถทำได้ด้วยคำสั่งนี้ใน command prompt (เช่น cmd ของ windows)
pip install ชื่อpackagesคำสั่งนี้เรียกครั้งเดียว เพื่อให้ computer เราโหลด script ของ library ตัวนี้มาจาก internet นะ ครั้งต่อๆ ไปก็ไม่ต้อง install แล้ว สามารถเรียกใช้ script ด้วยการ import มาใช้ในไฟล์เราได้เลย
อย่างไรก็ตาม การ install ใน colab จะใช้ syntax ที่ต่างไปเล็กน้อย เพื่อบ่งบอกว่านี่ไม่ใช้ script python แต่เป็น command line
!pip install ชื่อpackagesหรือ
%pip install ชื่อpackagesเราสามารถดูรายชื่อ module/packages ทั้งหมดที่ install ไว้แล้วได้ด้วยคำสั่ง
pip listซึ่งจะเห็นว่าใน colab มี module/packages ที่ install ไว้แล้วมากมาย ดังนั้นอาจไม่ต้องใช้ pip install ด้วยซ้ำ import ได้เลย!
วิธี import module
เราสามารถใช้คำสั่ง import ได้ดังนี้ (สั่งใน script python หรือ ใน Colab)
import ชื่อmoduleหรือจะใช้แบบนี้ก็ได้ เพื่อให้อ้างอิงชื่อ module ง่ายขึ้นในอนาคต
import ชื่อmodule as ชื่อเล่นลอง import เครื่องมือจัดการข้อมูลที่ชื่อ pandas
เจ้า pandas ถือเป็น module/packages ที่ค่อนข้างทำงานคล้ายกับการจัดการข้อมูลใน Excel มากๆ เลย จะเป็นไงมาดูกันครับ
อ่านไฟล์ csv ด้วย read_csv
สมมติว่าจะ import module ที่ชื่อว่า pandas มาใส่ชื่อเล่น pd แล้วลองอ่านไฟล์ csv ใน url ที่กำหนด ก็ทำตามนี้
จุดเด่นของ pandas คือการเก็บข้อมูลในลักษณะที่เรียกว่า dataframe ซึ่งมีวิธีการทำงานคล้ายกับ table ใน excel มากๆ
myFileURL='https://raw.githubusercontent.com/ThepExcel/download/master/ThepExcelsample.csv'
import pandas as pd
myDataFrame=pd.read_csv(myFileURL) #อ่านไฟล์ csv ไว้ใน dataframe (โครงสร้างข้อมูลใน pandas)
myDataFrame.head() #แสดงตัวอย่าง 5 บรรทัดแรก (ถ้าใส่เลข ก็จะเอาตามจำนวนนั้น)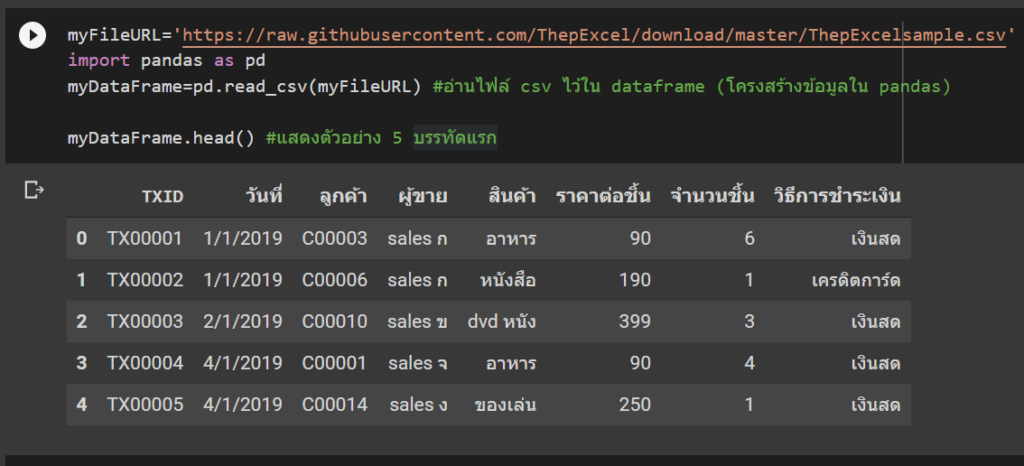
ถ้าจะทำความเข้าใจภาพรวมของข้อมูลก็สามารถใช้คำสั่งนับแบบไม่ซ้ำได้ดังนี้
myDataFrame.nunique() # นับข้อมูลแบบไม่ซ้ำในแต่ละคอลัมน์
วิธีอ้างอิงคอลัมน์
เราสามารถอ้างอิงคอลัมน์ที่ต้องการได้คล้ายๆ การอ้างอิง Table ใน Excel เลย เช่น myDataFrame[‘จำนวนชิ้น’] จะเป็นการอ้างอิงคอลัมน์จำนวนชิ้น หรือจะเขียนแบบนี้ก็ได้ myDataFrame.จำนวนชิ้น (แต่วิธีนี้ ที่ผมลองมักมีปัญหากับภาษาไทย T_T)
ซึ่งสามารถเอาไปใช้ทำอย่างอื่นต่อได้อีก เช่น เราจะสร้างคอลัมน์ยอดขายขึ้นมาใหม่จาก ราคาต่อชิ้น * จำนวนชิ้น ก็ทำได้เหมือนเขียนสูตรใน Table Data Model ของ Excel หรือ Power BI เลย
myDataFrame['ยอดขาย']=myDataFrame['ราคาต่อชิ้น']*myDataFrame['จำนวนชิ้น'] #สร้างคอลัมน์ยอดขาย
myDataFrame.describe() #สรุปข้อมูลที่เป็นตัวเลขออกมา (เห็นคอลัมน์ใหม่แล้ว)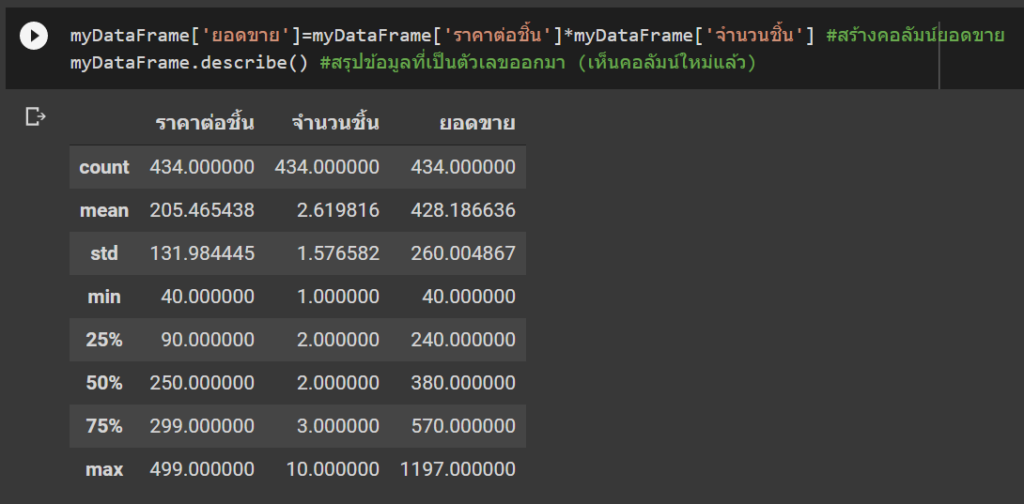
การ Filter ข้อมูลตามเงื่อนไข
ถ้าจะ filter ข้อมูล ก็ใส่เงื่อนไขที่ต้องการในลักษณะนี้ได้เลย
ชื่อDataFrame[เงื่อนไข] #เงื่อนไข เช่น ชื่อDataFrame['คอลัมน์']== ค่าบางอย่างซึ่งถ้าเงื่อนไขมันซับซ้อน จะเขียนแยกไว้ก่อน แล้วค่อยเอามาใช้ทีหลังก็ได้ เช่น
cond1=เงื่อนไข1
cond2=เงื่อนไข2
condFinal=เงื่อนไข1 & เงื่อนไข2
ชื่อDataFrame[condFinal]เช่น ถ้าจะ filter ให้เป็น sales ก ขาย หนังสือ ก็ทำแบบนี้ได้
cond1=myDataFrame['ผู้ขาย']=='sales ก'
cond2=myDataFrame['สินค้า']=='หนังสือ'
cond3=myDataFrame['จำนวนชิ้น']>5
condFinal = (cond1 & cond2) | cond3 #(cond1 และ cond2) หรือ cond3
myFilterData=myDataFrame[condFinal]
myFilterData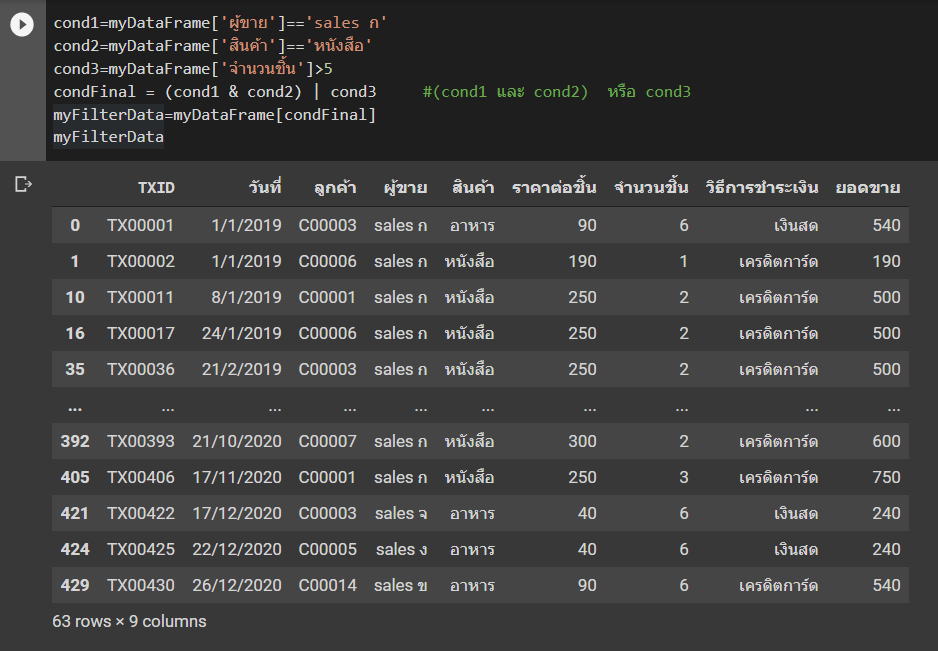
สรุปข้อมูลด้วย groupby และ pivot_table
ถ้าจะสรุปข้อมูล ก็ทำได้ง่ายๆ ด้วยคำสั่ง groupby() ซึ่งจะคล้ายกับใช้ Pivot แล้วลาก Field ไปไว้ที่ Rows ของ Pivot เช่น
myDataFrame.groupby(['สินค้า','วิธีการชำระเงิน']).sum() #สรุปข้อมูลได้ด้วย groupby
หรือถ้าจะใส่ 2 แกน cross กัน แบบ PivotTable จริงๆ ก็ทำได้เช่นกันครับ ซึ่งใน pandas ก็มี pivot_table ให้ใช้เช่นกัน ซึ่งจริงๆ มันปรับแต่งอะไรได้เยอะมากนะ แต่อันนี้แค่เป็นตัวอย่างง่ายๆ เฉยๆ
pd.pivot_table(myDataFrame,values='ยอดขาย', index=['สินค้า','วิธีการชำระเงิน'], columns=['ผู้ขาย'], aggfunc='sum')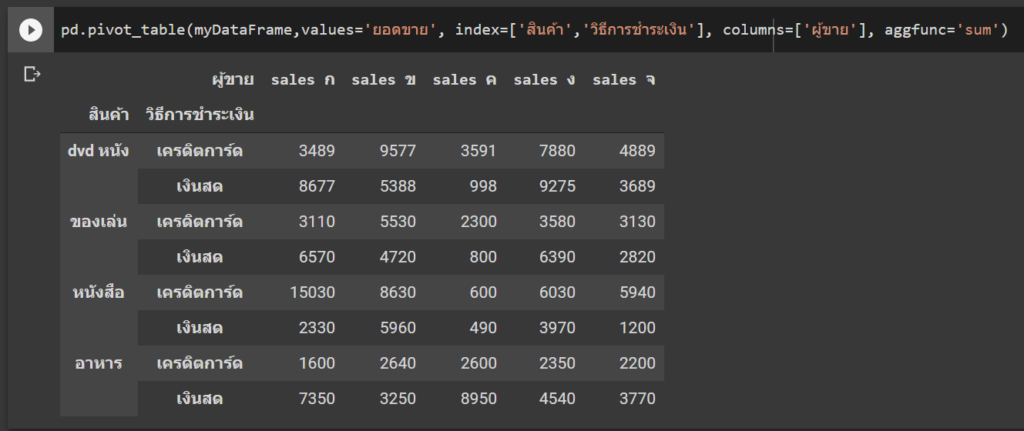
ถ้าหากเราอยากได้วิธีการสรุปข้อมูลแปลกๆ เราอาจใช้วิธี import packages อื่นมาอีกก็ได้ เช่น numpy
ลอง import เครื่องมือคำนวณตัวเลขที่ชื่อ numpy
ลองคำนวณ percentile ที่ 70 ดู ซึ่งเราใช้วิธีเรียกใช้ฟังก์ชันจาก Module ชื่อ numpy มาคำนวณ (เราสร้างฟังก์ชันเองก็ได้นะ) ซึ่งการคำนวณแปลกๆ แบบนี้ Pivot Table ธรรมดาใน Excel ทำไม่ได้ตรงๆ เช่นกันนะ ต้องใช้ Power Pivot ที่มี DAX Measure ถึงจะทำได้
import numpy as np
pd.pivot_table(myDataFrame,values='ยอดขาย', index=['สินค้า','วิธีการชำระเงิน'], columns=['ผู้ขาย'], aggfunc=lambda x: np.percentile(x, 70))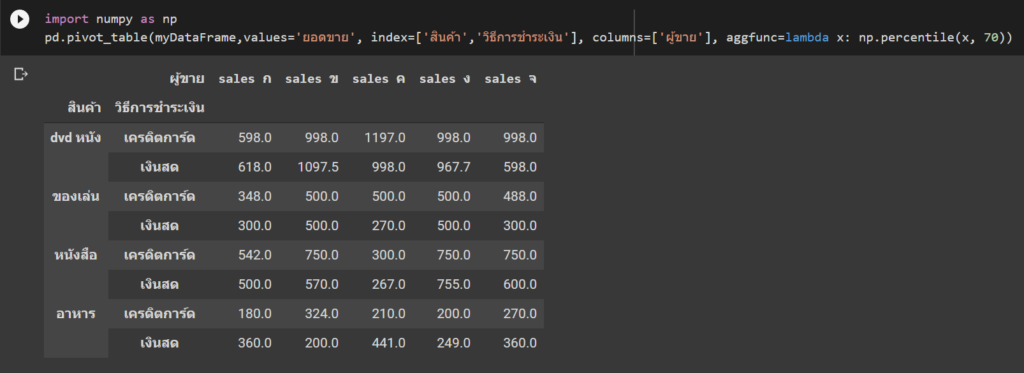
ลอง Plot Graph ออกมาดูด้วย Matplotlib
จริงๆ การ plot ไม่ได้ยุ่งมาก แต่ถ้าใช้ font ภาษาไทยจะยุ่งนิดนึง อาจต้อง import matplotlib และ install font ภาษาไทยด้วยดังนี้
!wget https://github.com/Phonbopit/sarabun-webfont/raw/master/fonts/thsarabunnew-webfont.ttf
# !pip install -U --pre matplotlib
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.font_manager.fontManager.addfont('thsarabunnew-webfont.ttf') # 3.2+
mpl.rc('font', family='TH Sarabun New')จากนั้นก็ plot กราฟได้แล้ว ซึ่งผมจะลองวน loop เลือก filter data มา plot ทีละผู้ขาย ซึ่งขอยังไม่อธิบาย syntax เรื่องของการทำกราฟตอนนี้นะครับ
for i in sorted(set(myDataFrame['ผู้ขาย'])):
selectedSales= myDataFrame[myDataFrame['ผู้ขาย']==i]
#myDataFrame['ผู้ขาย']==i ได้ T/F
SalesAmtbyProduct=selectedSales.groupby('สินค้า')['ยอดขาย'].sum()
SalesAmtbyProduct.plot(kind='bar',x='สินค้า',y='ยอดขาย',title=i)
plt.show()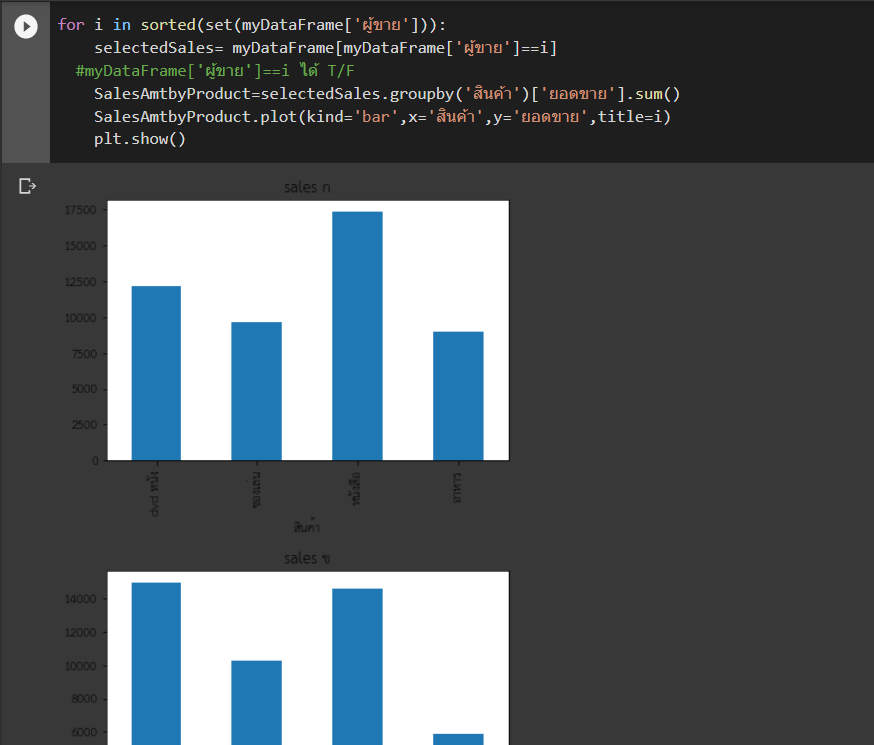
ตอนต่อไป
นี่ก็เป็นตัวอย่างเล็กๆ น้อยๆ ของการ import packages ต่างๆ มาใช้ ซึ่งจะเพิ่มความสามารถของโปรแกรมเราได้อีกมากมาย โดยเราไม่จำเป็นต้องเขียนความสามารถนั้นๆ ขึ้นมาเองเลย แค่คิดว่าในสถานการณ์นั้นๆ เราต้องการความช่วยเหลือด้านไหน ก็ไปหา packages ด้านนั้นมาแค่นั้นเอง (แต่ความยากคือ ต้องไปศึกษา syntax ของ packages นั้นๆ อีกอ่ะนะ)
ในตอนต่อไปจะมาเจาะลึก packages สำคัญๆที่ละตัว เพื่อให้เราทำงานได้ดียิ่งขึ้นกันครับ
สารบัญ Series Python
- หัดเขียนโปรแกรม Python สำหรับคนเป็น Excel มาก่อน : ตอนที่ 1
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 2 – ประเภทข้อมูล (Data Types)
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 3 – การวน Loop และ เงื่อนไข if
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 4 – การทำงานกับ String และ List
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 5 – การสร้างฟังก์ชันขึ้นมาใช้เอง (Function)
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 6 – การเรียกใช้ Module / Packages เจ๋งๆ ที่มีคนสร้างไว้แล้ว
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 7 – Web Scraping ด้วย Beautiful Soup
- แนวทางการใช้ Python ใน Power BI
- หัด Python สำหรับคนเป็น Excel : ตอนที่ 8 – การสร้างกราฟด้วย Matplotlib
- รวม Link สอน Python / Programming / AI/ Machine Learning แบบฟรีๆ
- สอนใช้ Python ใน Excel ตอนที่ 1 : ลองใช้ครั้งแรก
- สอนใช้ Python ใน Excel ตอนที่ 2 : List, Loop, Condition
- สอนใช้ Python ใน Excel ตอนที่ 3 : Regular Expression (RegEx)
- สอนใช้ Python ใน Excel ตอนที่ 4 : สร้างฟังก์ชันใช้เอง
- สอนใช้ Python ใน Excel ตอนที่ 5 : สร้างกราฟ Visualization เบื้องต้นด้วย Matplotlib
- การวิเคราะห์ข้อมูลเบื้องต้นด้วย Python: เริ่มต้นด้วย Pandas และ Matplotlib
- เพิ่มยอดขายด้วย Market Basket Analysis : วิเคราะห์คู่สินค้าขายดีด้วย Python


Leave a Reply