
สวัสดีครับ สำหรับบทความนี้ ผมจะพาทุกท่านมาเรียนรู้การประยุกต์ใช้ Python ใน Excel เพื่อทำ Machine Learning กัน ถือเป็นการผสมผสานระหว่าง Spreadsheet ที่เราคุ้นเคย เข้ากับ Python ที่เป็นภาษายอดนิยมสำหรับการวิเคราะห์ข้อมูล เพื่อให้สามารถทำ Data Science ได้อย่างง่ายดาย
ก่อนหน้านี้ผมได้มีการเขียนบทความเกี่ยวกับ Python ใน Excel ไว้บ้างแล้ว ในตอนนี้ผมจะลองใช้มันมาทำ Machine Learning หลายๆ แบบดูครับ
สารบัญ
สรุปสิ่งที่ต้องรู้ก่อน
ก่อนอื่นมาทำความเข้าใจพื้นฐานกันก่อน:
- Python ใน Excel เป็น Beta feature ของ Excel 365 ดังนั้นจึงมีเงื่อนไขคือ:
- ต้องมี Excel 365 และสมัครเป็น Insider แบบ Beta Channel
- Python จะทำงานแบบ Cloud ไม่ได้ติดตั้งในเครื่อง ต้องออนไลน์ตลอด และใช้ได้เฉพาะ Library ที่มีให้
- Python ใน Excel เน้นไปที่การทำ Data Analysis และ Visualization ไม่ได้ออกแบบมาเพื่อ Automation
- การใช้ Python ใน Excel ทำได้โดย:
- พิมพ์ =PY ลงใน Cell แล้วเขียน Code Python ต่อจากนั้น
- กด Ctrl+Enter เพื่อรันโค้ด
- Python จะอ่านข้อมูลทีละแถวจากซ้ายไปขวา แล้วค่อยไปแถวถัดไป
- การอ่านข้อมูลจาก Excel เข้ามาใน Python ทำได้ง่ายๆ ผ่านฟังก์ชัน =xl()
- xl() สามารถอ่านได้ทั้ง Range, Dynamic Array, Table หรือ Power Query
- ผลลัพธ์จะได้เป็น DataFrame ของ Python เสมอ
- สามารถเลือก Output เป็น Python Object หรือ Excel Value (Dynamic Array) ได้
ต้องใช้ Python เป็นแค่ไหน?
สำหรับคนที่เขียน Python ไม่เก่ง (ซึ่งผมเองก็ไม่เก่ง) ผมแนะนำว่าควรใช้ AI อย่าง ChatGPT ช่วยเขียน Code แล้วเราค่อยมาปรับแต่งอีกที
เราจะมีความรู้ Python ในระดับอ่าน Code ได้ พอจะแก้ไขได้บ้างนิดหน่อย ซึ่งผมได้อธิบายเรื่องพวกนี้ไปในบทความก่อนหน้านี้แล้ว
ซึ่งผมได้มีการทำ GPTs AI Chatbot เพื่อช่วยตอบเรื่องนี้ให้ในระดับนึงไว้แล้ว สามารถไปลองเล่นได้ที่นี่

มาลองทำ Machine Learning เบื้องต้นกัน ผมจะเอา Tutorial ตัวนี้มาประยุกต์นะครับ https://www.youtube.com/watch?v=hDKCxebp88A แล้วจะเอา Dataset ที่เค้าใช้มาทำเลย
นำข้อมูลเข้า
Data เป็นเรื่องของให้ Predict ค่าใช้จ่ายของลุกค้าใหม่ที่มาสมัครประกัน ซึ่ง URL ของไฟล์อยู่ที่นี่ https://raw.githubusercontent.com/JovianML/opendatasets/master/data/medical-charges.csv
เอา Data เข้าสู่ Power Query
ก่อนอื่น ในฐานะของ Excel User เราจะใช้ Power Query ดึง Data มานะครับ (ใช้ Python ก็ได้ แต่ผมจะใช้ Power Query เพราะถนัดมากกว่า)
ขั้นตอนแรกคือการดึงข้อมูลเข้า Power Query ก่อน ทำได้โดยใช้ Get Data from Web แล้วใส่ URL ข้างต้น จากนั้นโหลดมาแบบ Connection Only แล้วตั้งชื่อ Query ว่า “MedicalData”
เอา Data จาก Query เข้าสู่ Python
ต่อไปเราจะส่งข้อมูลตัวอย่างไป 50 แถวแรกให้ AI เพื่อให้มันแนะนำการเขียนโค้ดที่เหมาะสม เราจะขอคำแนะนำว่าควรทำอย่างไรถึงจะโหลดข้อมูลจาก Query เข้าสู่ Python DataFrame ชื่อ medical_df ได้
ผม Copy ข้อมูลซัก 50 บรรทัดแรกไปปรึกษา AI ก่อน แล้วบอกมันว่า
ผมมี data แบบนี้ โดยที่อยู่ใน Query ชื่อ MedicalData แล้วอยากเอาเข้า python ใน excel ตั้งชื่อ DataFrame ว่า medical_df
เมื่อส่งข้อมูลตัวอย่างและ Prompt ไป AI ก็ตอบกลับมาว่าให้เขียนโค้ดแบบนี้:
(ถ้าอ่าน eng ไม่เข้าใจ ให้มันอธิบายเป็นภาษาไทยได้นะ แต่ eng จะฉลาดกว่าและเร็วกว่า)

เราเขียนโค้ดตามที่แนะนำ โดยเริ่มจากพิมพ์ =PY กด tab จากนั้นแล้วเอาข้อมูลเข้าด้วย xl แบบนี้ (สามารถจิ้มที่ cell ว่างๆ จะขึ้น =xl มาเอง แล้วแก้ข้างในเป็นชื่อ Query)
ผมลองคำสั่งแรกก่อน คือ การเอา DataFrame เข้า

เริ่มสำรวจข้อมูล
ถ้าเราใช้ describe() ตามที่มันบอก มันก็จะมีผลสรุปมาให้แบบนี้
เราสามารถกดเปลี่ยน Python Object ให้เป็น Excel Value ได้ (กดข้างๆ PY ตรง Formula Bar หรือจะกดคีย์ลัด Ctrl+Alt+Shift+M ก็ได้)

ทีนี้เราถาม AI ต่อว่า ถ้าอยากจะ Predict Charges ควรจะทำยังไง?
มันก็จะบอกว่ามีขั้นตอนประมาณนี้
- การเตรียมข้อมูล (Data Preprocessing): ตรวจสอบให้แน่ใจว่าข้อมูลสะอาดและอยู่ในรูปแบบที่ถูกต้องสำหรับการวิเคราะห์
- การเลือกคุณลักษณะ (Feature Selection): ตัดสินใจว่าคุณลักษณะ (คอลัมน์) ใดในข้อมูลที่อาจมีอิทธิพลต่อค่าใช้จ่าย (charges)
- การแบ่งข้อมูล (Data Splitting): แบ่งข้อมูลของคุณออกเป็นชุดฝึกฝน (training set) และชุดทดสอบ (testing set)
- การเลือกโมเดล (Model Selection): เลือกโมเดลการเรียนรู้ของเครื่อง (machine learning model) ที่เหมาะสมสำหรับการถดถอย (regression) เนื่องจาก
chargesเป็นตัวแปรต่อเนื่อง - การฝึกโมเดล (Model Training): ฝึกโมเดลโดยใช้ชุดฝึกฝน
- การประเมินโมเดล (Model Evaluation): ประเมินประสิทธิภาพของโมเดลด้วยชุดทดสอบ
- การพยากรณ์ (Prediction): ใช้โมเดลในการทำนายผล
เบื้องต้นมันให้ code มาชุดนึงแบบนี้เลย
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Assuming 'medical_df' is already loaded with the data
# Step 1: Preprocess Data
# Convert categorical variables to numerical ones using one-hot encoding.
medical_df = pd.get_dummies(medical_df)
# Step 2: Feature Selection
# We will use all columns except 'charges' as features to predict 'charges'.
X = medical_df.drop('charges', axis=1) # Features
y = medical_df['charges'] # Target variable
# Step 3: Data Splitting
# Split the dataset into a training set and a testing set.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 4 & 5: Model Selection and Training
# Create a linear regression model and train it with the training data.
model = LinearRegression()
model.fit(X_train, y_train)
# Step 6: Model Evaluation
# Predict charges for the testing set and evaluate the model's performance.
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# The mean squared error and R-squared value give us an idea of the model's performance.
mse, r2
# Step 7: Prediction
# Use the trained model to predict charges based on a new set of features.
# Here's an example using the first row from the test set:
example = X_test.iloc[0]
predicted_charge = model.predict([example])
# The variable 'predicted_charge' now holds the predicted value for the charges.
predicted_charge
# Note: No print statements needed, as we assign the output to variables.
ซึ่งถ้าเราเอา code ทั้งยวงไปใช้เลย แทนใน Cell เดิม (A3)
เหมือนว่ามันจะได้เลขที่เป็นผล Predict ไปเลย คือ 8969.55 (เลขแต่ละคนอาจไม่เหมือนกัน เพราะจริงๆ มัน random ทดสอบ) ซึ่งตอนนี้เราอาจยังไม่รู้ว่ามัน Predict อะไรออกมาด้วยซ้ำ เดี๋ยวเราจะลองเอาค่าของแต่ละ Step ออกมาดู โดยเอาตัวแปรนั้นมาเรียกอีกทีในตอนจบ จะดีกว่า
Tips : ปรับการคำนวณเป็น Manual ก่อน จะเร็วกว่า
ถ้าเรามีการคำนวณหลายช่อง ผมแนะนำให้ปรับการคำนวณเป็น Manual ก่อน จะเร็วกว่า เพราะมันจะได้ไม่ต้องส่ง Code ทุกช่องที่เคยรันแล้วไปคำนวณใหม่ตลอดเวลา
แต่ถ้าเรามีการกลับไปแก้ Code ใน Cell เดิม อย่าลืมกด F9 เพื่อ Recalculate ด้วยนะ
ดูผลลัพธ์ทีละ Step
เดี๋ยวเราจะลองเอาค่าของแต่ละ Step ออกมาดู โดยเอาตัวแปรนั้นมาเรียกอีกทีในตอนจบ เช่น เราจะลองเรียกดูค่า medical_df โดยเรียกดูใน Cell ด้านขวาหรือด้านล่างของ Code ชุดใหญ่ที่เราใส่ไว้
medical_dfเช่น แบบนี้

ลองรันโค้ดแล้วก็จะเจอปัญหาว่า การใช้ pd.get_dummies() เพื่อสร้าง Dummy Variables ให้กับข้อมูลประเภท Categorical นั้นใน Python ของ Excel จะได้ค่าเป็น True/False แทนที่จะเป็น 1/0
AI มันจะบอกว่า ให้เราทำแบบนี้ เพื่อบังคับให้เป็น int
medical_df = medical_df.astype(int)จึงต้องเพิ่ม Code ในส่วนของ Data Preprocessing โดยใช้ astype(int) เพื่อแปลง True/False ให้เป็น 1/0
ดังนั้นผมจะแก้สูตรโดยเอาค่านี้ไปต่อจากคำว่า medical_df = pd.get_dummies(medical_df) ใน Step1 ซึ่งจะกลายเป็น
# Step 1: Preprocess Data
# Convert categorical variables to numerical ones using one-hot encoding.
medical_df = pd.get_dummies(medical_df)
medical_df = medical_df.astype(int)ซึ่งถ้าเราแก้จะได้แบบนี้ คือเป็น 1,0 ละ ถือว่าใช้ได้

คราวนี้เราก็มาดู Step ถัดไปได้ละ ถ้าเราลองดูสูตรของค่า X กับ Y ที่มาจาก Step2 มันคือแค่การแยกว่า X คือตัวแปรต้น (Features) และ y คือตัวแปรตาม คือ Charges
ส่วนนี้ Code เดิม เค้าแค่กำหนดตัวแปร X กับ y ว่า X คือ Features ที่จะใช้ (ในที่นี้มันเอาทุกอันยกเว้น Charges เพราะมัน drop ทิ้งไป) และ y คือ target ที่เราต้องการ Predicts
# Step 2: Feature Selection
# We will use all columns except 'charges' as features to predict 'charges'.
X = medical_df.drop('charges', axis=1) # Features
y = medical_df['charges'] # Target variableซึ่งเอาเข้าใจเราต้องดูด้วยว่า features มัน Make sense ไหม แล้วซ้ำซ้อนไหม? เช่นพวก Transaction id, customer id อะไรแบบนี้ไม่ควรเอามาเป็น Feature นะ แต่ในเคสนี้เราไม่มี ก็เลยไม่เป็นไร
จากนั้นลองกลับมาดูข้อมูลอีกครั้ง เพื่อตรวจสอบว่ามีคอลัมน์ที่อาจจะซ้ำซ้อนหรือไม่เหมาะที่จะนำมาใช้ทำนายหรือไม่ พบว่ามีคอลัมน์ sex_female กับ smoker_no ที่สามารถ drop ออกไปได้เลย เพราะมันตรงข้ามกับ sex_male และ smoker_yes อยู่แล้ว
ดังนั้นเราจะแก้สูตรของ medical_df ให้ drop [‘sex_female’,’smoker_no’] ไปเลย
# Step 1: Preprocess Data
# Convert categorical variables to numerical ones using one-hot encoding.
medical_df = pd.get_dummies(medical_df)
medical_df = medical_df.astype(int)
medical_df = medical_df.drop(['sex_female','smoker_no'],axis=1)จากนั้นเราลองเอาค่า X มาดู จะเห็นว่า Field ที่ซ้ำซ้อนหายไปแล้ว

ถ้าเราลองใส่ Code ไปว่า
X.shapeเราก็จะรู้ขนาดของ DataFrame X ซึ่งจะได้ว่าเป็น Tuple ขนาด 1338, 9 ซึ่งก็คือ จำนวน 1338 แถว 9 คอลัมน์นั่นเอง
สูตรต่อไปเป็นการแยกข้อมูล Training Set กับ Test Set อันนี้มันกำหนด Test size = 0.2 ก็คือ 20% ซึ่งก็ดู ok ทำให้ X ก็เลยแยกเป็น 2 ชุด คือ X_train, X_test และ y ก็กลายเป็น y_train, y_test
# Step 3: Data Splitting
# Split the dataset into a training set and a testing set.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)ถ้าเราลอง X_train.shape จะได้ 1070 แถว 9 คอลัมน์ และ X_test.shape จะได้ 268 แถว 9 คอลัมน์ ซึ่งถ้ารวมกันก็คือกลับไปเท่ากับ X ที่ 1338 แถวนั่นเอง
ต่อไปเป็นการเลือก Model
# Step 4 & 5: Model Selection and Training
# Create a linear regression model and train it with the training data.
model = LinearRegression()
model.fit(X_train, y_train)มันมองว่า ข้อมูลของเราเหมาะกับการทำ Linear Regression ก็เลยเลือก Model แบบนี้มาให้ ซึ่งพอถามไปปุ๊ปมันก็แนะนำว่า ควรจะ Visualize ข้อมูลดูก่อนว่ามีความเป็นเส้นตรงจริงไหม
ก็เลยจะลอง Plot แบบนี้ดู
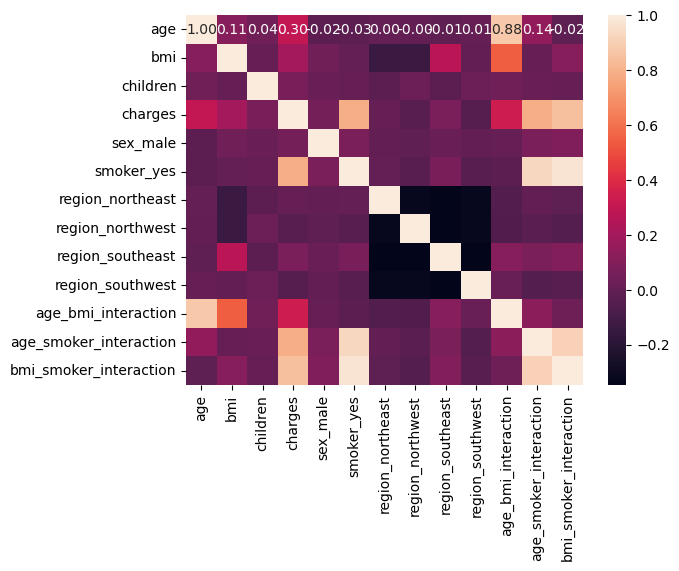
Correlation Matrix
# Compute the correlation matrix
corr_matrix = medical_df.corr()
# Generate a heatmap
sns.heatmap(corr_matrix, annot=True, fmt=".2f")พอกดให้เป็น Excel Value จะเป็นรูปเล็กๆ ใน Cell
พอเลือกที่ Cell ที่มีรูปจะมี Link ออกมาเป็นรูปใหญ่ให้ ขยายได้ตามใจชอบ ได้กราฟแบบนี้ (กด save as picture ได้)
Scatter Matrix
ถ้าทำ Scatter Matrix แบบนี้
# Generate a scatter matrix
pd.plotting.scatter_matrix(medical_df, figsize=(10, 10))จะเห็นความสัมพันธ์ของทุกตัวแปรซึ่งอาจเยอะไป
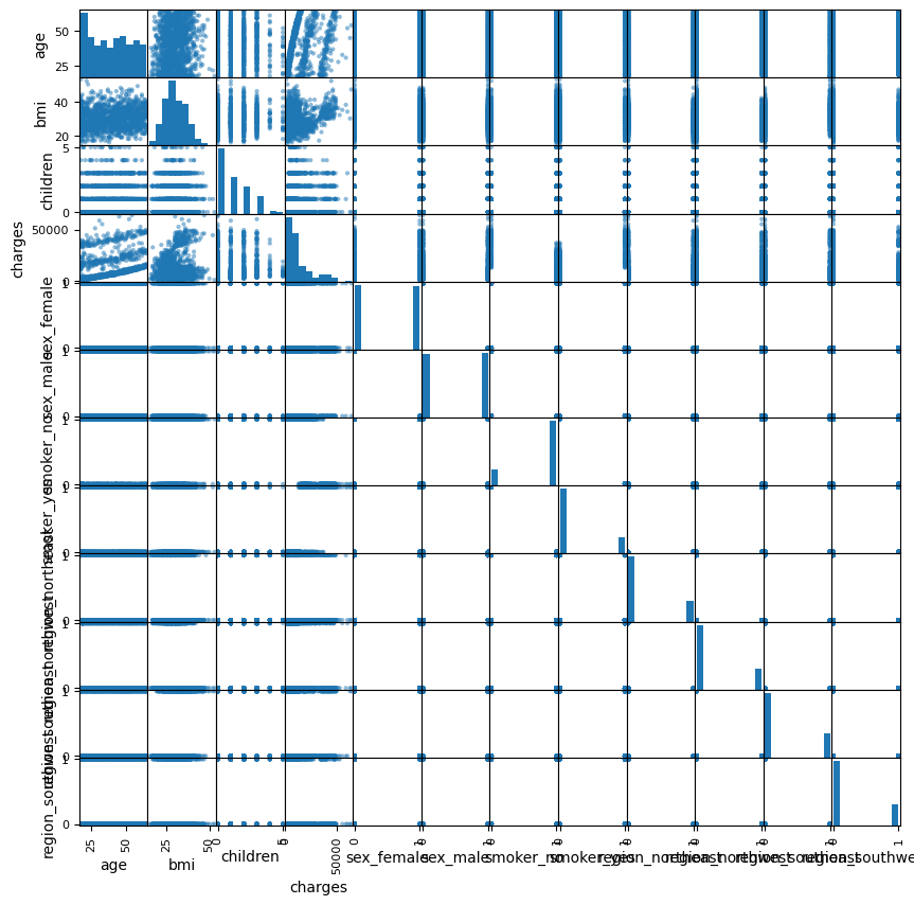
ดังนั้นผมเอาแค่ 4 คอลัมน์แรกพอ เลยใช้ iloc slice ตัว DataFrame ออกมาแค่นี้ และจะเห็น scatter และ distribution ชัดเจนขึ้นด้วย
# Generate a scatter matrix
pd.plotting.scatter_matrix(medical_df.iloc[:, :4], figsize=(10, 10))
จากรูป เราจะเห็นว่า ค่า Charges ก็ดูมีความสัมพันธ์กับ อายุ และ bmi พอสมควร ก็น่าจะลองใช้ Linear Regression ได้ ก็ลองใช้ดู
และ Step 6 คือการวัดผลของการ Predict ว่าแม่นแค่ไหน
# Step 6: Model Evaluation
# Predict charges for the testing set and evaluate the model's performance.
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# The mean squared error and R-squared value give us an idea of the model's performance.
mse, r2ลองใส่ดูค่า mse, r2 จะได้ค่า mse กับ r2 เป็น 20984146.18 และ 0.86483504
ตามลำดับ
จากนั้น Step7 ลองทำการ Predict โดยที่มันเอาค่าจาก Row แรกไปเข้า Model ดูเฉยๆ ซึ่งมันเอาค่าจาก X_test ตัวแรกมาดู
# Step 7: Prediction
# Use the trained model to predict charges based on a new set of features.
# Here's an example using the first row from the test set:
example = X_test.iloc[0]
predicted_charge = model.predict([example])
# The variable 'predicted_charge' now holds the predicted value for the charges.
predicted_chargeซึ่งถ้าเราอยากรู้ว่าของจริงได้เท่าไหร่ ก็ลองเอา y_test ออกมาดูเทียบกัน โดยใช้
predicted_charge[0],list(y_test)[0]ผลออกมาได้ 9087.642154 ซึ่งของจริงคือ 9095 ก็พบว่าใกล้กันใช้ได้เลย
เดี๋ยวให้มันลองทำเป็นกราฟดีกว่า ว่าเทียบกันแล้วกับ Actual Data แล้ว Model เราเป็นยังไง
Plot Check
Actual vs Predict Scatter Plots
plt.scatter(y_test, y_pred)
plt.xlabel("Actual Charges")
plt.ylabel("Predicted Charges")
plt.title("Actual vs Predicted Charges")
plt.show()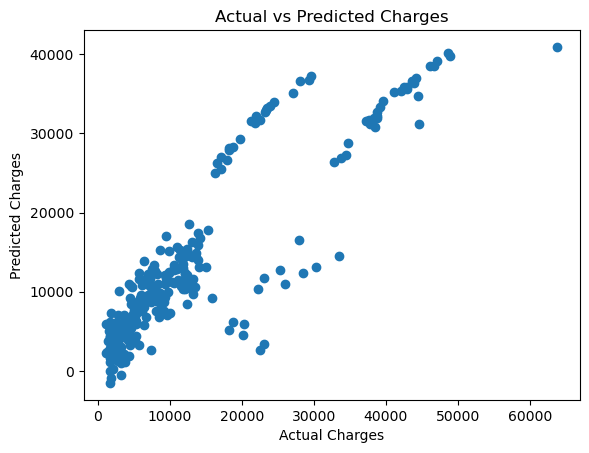
Residual Plots
residuals = y_test - y_pred
plt.scatter(y_pred, residuals)
plt.hlines(y=0, xmin=y_pred.min(), xmax=y_pred.max())
plt.xlabel("Predicted Charges")
plt.ylabel("Residuals")
plt.title("Predicted vs Residuals")
plt.show()
จากกราฟ Scatter มันดูเหมือนมีเส้น 2 แฉกแยกจากกัน และจาก Residual Plots มันดูมีการแบ่งกลุ่มบางอย่างเป็นหลายๆ ก้อน แสดงว่าอาจต้องมีการทำ Feature Engineering (การดัดแปลง Features) ก่อน เพื่อให้ผลลัพธ์ดีขึ้น
ทำ Interaction Features เพิ่ม
ดังนั้นเราจะลองทำอะไรบางอย่างกับ Data เช่น ลองเพิ่ม Features ที่จะมี Interaction กัน เช่น ถ้าเราสงสัยว่า คนที่สูบบุหรีกับไม่สูบ อาจมีผลกับ BMI หรือ อายุ ต่างกัน ดังนั้นอาจทำ interaction ดู
โดยผมจะเพิ่มพวกนี้เข้าไประหว่าง Steps 1 กับ 2 ไปเลย
# Create interaction between 'age' and 'bmi'
medical_df['age_bmi_interaction'] = medical_df['age'] * medical_df['bmi']
# Create interaction between 'age' and 'sex_male'
medical_df['age_sex_interaction'] = medical_df['age'] * medical_df['sex_male']
# Create interaction between 'age' and 'smoker'
medical_df['age_smoker_interaction'] = medical_df['age'] * medical_df['smoker_yes']
# Create interaction between 'bmi' and 'sex_male'
medical_df['bmi_sex_interaction'] = medical_df['bmi'] * medical_df['sex_male']
# Create interaction between 'bmi' and 'smoker'
medical_df['bmi_smoker_interaction'] = medical_df['bmi'] * medical_df['smoker_yes']
# Create interaction between 'sex_male' and 'smoker'
medical_df['sex_smoker_interaction'] = medical_df['sex_male'] * medical_df['smoker_yes']ก็จะได้ผลว่า ค่า R2 ได้พอๆ กับอันเดิมเลย อันนี้ได้ 0.864307685
ซึ่งตรงนี้มันอาจขึ้นอยู่กับโชค ในการแบ่ง Training, Test Set ก็ได้
ทำ Cross Validation
ดังนั้นเราจะลองทำ Cross Validation เพื่อทดสอบ Training vs Test หลายๆ แบบ
from sklearn.model_selection import cross_val_score
# Using cross-validation to evaluate the model
cv_scores = cross_val_score(model, X, y, cv=10, scoring='r2')
cv_scores.mean()ซึ่งแบบ interaction เฉลี่ย cv_scores.mean() จะได้ 0.835941331 แต่ถ้าก่อนที่เราจะใส่ interaction เข้าไป ค่านี้จะได้ 0.744484494
แปลว่าตอนแรกที่ได้ r2 เยอะ ก่อนใส่ interaction คือ ฟลุ๋คนั่นเอง แต่พอใส่ interaction ไป ค่า r2 เยอะขึ้นจริง
Actual vs Predict Scatter Plots

Residual

ค่าที่ได้กระจายดีขึ้น
สมการที่ใช้ Predict
ถ้าอยากรู้ว่าสมการเป็นยังไง อาจลองใช้ code นี้
intercept = model.intercept_
coefficients = model.coef_
feature_names = X.columns.tolist()
equation = f'y = {intercept:.2f}'
for coef, name in zip(coefficients, feature_names):
equation += f' + ({coef:.2f})*{name}'
equationจะได้สมการแบบนี้
y = -242.19 + (208.22)age + (-50.69)bmi + (466.98)children + (-1707.34)sex_male + (-20908.90)smoker_yes + (719.62)region_northeast + (87.76)region_northwest + (-272.08)region_southeast + (-535.30)region_southwest + (1.56)age_bmi_interaction + (14.14)age_sex_interaction + (3.12)age_smoker_interaction + (17.01)bmi_sex_interaction + (1470.82)bmi_smoker_interaction + (560.50)*sex_smoker_interaction
เลขอาจดูแปลกนิดหน่อย เพราะมันมี interaction มาเกี่ยวด้วย เช่น smoker_yes เลขมันดันติดลบตั้ง -20908.90 เหมือนว่าสูบบุหรี่แล้วค่าเบี้ยต่ำลง แต่จริงๆ แล้วไม่ใช่ เพราะมันมี
+ (3.12)age_smoker_interaction + (1470.82)bmi_smoker_interaction + (560.50)*sex_smoker_interaction อยู่อีก
เช่น สมมติเป็นคนสูบบุหรี่ เพศชาย อายุ 30 และ bmi 22 นี่ก็โดนบวกไป 33,012.14 แล้วเป็นต้น ซึ่งมัน offset กับ -20704.90 เป็น + net ที่ 12307.24 นั่นเอง
สรุปสิ่งที่ได้ตอนนี้
Code ณ ตอนนี้ (ผมไม่เอา Step7 แต่ใส่ Cross Validation แทน)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Assuming 'medical_df' is already loaded with the data
# Step 1: Preprocess Data
# Convert categorical variables to numerical ones using one-hot encoding.
medical_df = pd.get_dummies(medical_df)
medical_df = medical_df.astype(int)
medical_df = medical_df.drop(['sex_female','smoker_no'],axis=1)
# Create interaction between 'age' and 'bmi'
medical_df['age_bmi_interaction'] = medical_df['age'] * medical_df['bmi']
# Create interaction between 'age' and 'sex_male'
medical_df['age_sex_interaction'] = medical_df['age'] * medical_df['sex_male']
# Create interaction between 'age' and 'smoker'
medical_df['age_smoker_interaction'] = medical_df['age'] * medical_df['smoker_yes']
# Create interaction between 'bmi' and 'sex_male'
medical_df['bmi_sex_interaction'] = medical_df['bmi'] * medical_df['sex_male']
# Create interaction between 'bmi' and 'smoker'
medical_df['bmi_smoker_interaction'] = medical_df['bmi'] * medical_df['smoker_yes']
# Create interaction between 'sex_male' and 'smoker'
medical_df['sex_smoker_interaction'] = medical_df['sex_male'] * medical_df['smoker_yes']
# Step 2: Feature Selection
# We will use all columns except 'charges' as features to predict 'charges'.
X = medical_df.drop('charges', axis=1) # Features
y = medical_df['charges'] # Target variable
# Step 3: Data Splitting
# Split the dataset into a training set and a testing set.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 4 & 5: Model Selection and Training
# Create a linear regression model and train it with the training data.
model = LinearRegression()
model.fit(X_train, y_train)
# Step 6: Model Evaluation
# Predict charges for the testing set and evaluate the model's performance.
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# The mean squared error and R-squared value give us an idea of the model's performance.
mse, r2
from sklearn.model_selection import cross_val_score
# Using cross-validation to evaluate the model
cv_scores = cross_val_score(model, X, y, cv=10, scoring='r2')
cv_scores.mean()ซึ่งได้ cv scores mean เป็น 0.835941331
ถ้าลองเอาข้อมูลทั้งหมดมาเทียบกับ prediction แล้วทำ Visualization ดูจะเป็นแบบนี้
y_pred_full = model.predict(X)
# Actual vs Predicted scatter plot
plt.figure(figsize=(10, 6))
plt.scatter(y, y_pred_full, color='red', alpha=0.5) # 'y' should be your entire set of actual values
# Perfect prediction line
max_value = max(max(y), max(y_pred_full))
min_value = min(min(y), min(y_pred_full))
plt.plot([min_value, max_value], [min_value, max_value], color='green', linestyle='--', label='Perfect Fit')
plt.xlabel('Actual Charges')
plt.ylabel('Predicted Charges')
plt.title('Actual vs Predicted Charges for the Full Dataset')
plt.legend()
plt.show()
แล้วผมก็ส่งไปให้ AI ช่วยดู มันแนะนำแบบนี้
ข้อสังเกตและคำแนะนำจาก ChatGPT นั้นมีความสมเหตุสมผลและเป็นประโยชน์มากครับ ผมขอสรุปประเด็นหลักๆ ดังนี้
- โดยภาพรวมแล้ว โมเดลของเราทำนายได้ใกล้เคียงกับค่าจริงพอสมควร เห็นได้จากจุดข้อมูลจำนวนมากที่อยู่ใกล้กับเส้นสีเขียว (Perfect Fit) ซึ่งเป็นสัญญาณที่ดี แสดงว่าโมเดลมีความแม่นยำในระดับนึงแล้ว
- อย่างไรก็ตาม ยังมีรูปแบบความคลาดเคลื่อนที่เห็นได้ชัดคือ โมเดลมีแนวโน้มจะประเมินค่าต่ำไปสำหรับข้อมูลที่มีค่าจริงสูงๆ (Underpredict) และจะประเมินค่าสูงเกินไปสำหรับข้อมูลที่มีค่าจริงต่ำๆ (Overpredict) ซึ่งเห็นได้จากจุดที่ห่างออกจากเส้น Perfect Fit ค่อนข้างมาก
- ความแปรปรวนของค่าความคลาดเคลื่อน (Residuals) ดูเหมือนจะเพิ่มขึ้นตามขนาดของ Charge ซึ่งอาจเป็นสัญญาณของปัญหา Heteroscedasticity คือความแปรปรวนไม่คงที่ตลอดช่วงของตัวแปรต้น
ด้วยเหตุนี้ จึงมีแนวทางในการปรับปรุงโมเดลหลายอย่าง เช่น
- พิจารณาเพิ่มความซับซ้อนให้กับโมเดลให้มากขึ้น เช่น ใช้โมเดล Non-linear หรือเพิ่ม Interaction Term เพื่อจับความสัมพันธ์ที่ไม่ใช่เชิงเส้นตรงระหว่าง Features ต่างๆ
- ลองทำ Transformation กับตัวแปรตาม (Target) เช่น ใช้ Log เพื่อลดความเบ้และช่วยกระจายความแปรปรวนให้สม่ำเสมอมากขึ้น
- ทบทวน Features ที่ใช้อีกครั้ง อาจจะมีความสัมพันธ์แบบ Non-linear หรือมี Interaction ระหว่างกันที่ยังไม่ได้นำมาใช้
- ตรวจสอบ Outliers ที่อาจส่งผลกระทบอย่างมากต่อโมเดล โดยเฉพาะจุดที่ทำให้เกิด Under/Over predict
- สร้าง Diagnostic Plots เพิ่มเติม เช่น Residual Plot, QQ-Plot เพื่อวิเคราะห์ข้อมูลให้ลึกขึ้น
- ทำ Cross-Validation เพื่อยืนยันว่าประสิทธิภาพของโมเดลยังคงเดิมในข้อมูลหลายๆ ชุด ไม่ใช่แค่ Overfit กับ Training Set ชุดเดียว
สุดท้ายนี้ ผมเห็นด้วยว่าการสังเกตและวิเคราะห์จากกราฟนี้เป็นจุดเริ่มต้นที่ดีในการปรับปรุงโมเดลต่อไป โดยเราสามารถลองปรับเปลี่ยนตามข้อเสนอแนะข้างต้นทีละจุด แล้วกลับมาประเมินผลอีกครั้ง เพื่อเทียบว่าการเปลี่ยนแปลงนั้นช่วยพัฒนาโมเดลได้จริงหรือไม่
การทำ Machine Learning เป็นกระบวนการที่ต้องอาศัยการทดลองและปรับปรุงไปเรื่อยๆ จนกว่าจะได้โมเดลที่มีประสิทธิภาพสูงสุดครับ
สรุป
สุดท้ายนี้ขอสรุปว่าการทำ Machine Learning บน Excel โดยใช้ Python นั้นค่อนข้างทำได้ง่ายและเร็ว แถมยังใช้ประโยชน์จากความเก่งของ AI มาช่วยในการเขียนโค้ดอีกด้วย
ไม่จำเป็นต้องรู้ลึกมากก็สามารถเริ่มเล่น ML ได้แล้ว และสามารถค่อยๆ ปรับปรุงโมเดลไปได้เรื่อยๆ
หวังว่าบทความนี้จะเป็นประโยชน์สำหรับการเริ่มต้นเรียนรู้ Machine Learning บน Excel ด้วย Python นะครับ แล้วเจอกันใหม่ในตอนต่อไป ซึ่งเราจะมาดูการทำนายแบบอื่น เช่น แนวตอบเป็น yes,no บ้างครับ




Leave a Reply