ในยุคที่ข้อมูลเป็นพลังงานที่ขับเคลื่อนโลก การวิเคราะห์และการตีความข้อมูลเป็นทักษะสำคัญอย่างยิ่ง ไม่ว่าคุณจะเป็นนักเรียน นักธุรกิจ หรือผู้ที่สนใจด้านข้อมูล การศึกษาเกี่ยวกับการใช้ Python ในการทำงานกับข้อมูลสามารถเปิดโอกาสใหม่ ๆ ได้อย่างมาก บทความนี้ผมจะสอนพื้นฐานการวิเคราะห์ข้อมูลด้วย Pandas และการสร้างกราฟด้วย Matplotlib ซึ่งเป็น library หรือเครื่องมืออย่างหนึ่งที่มาคู่กับ Python โดยคุณไม่จำเป็นต้องมีพื้นฐานการเขียนโปรแกรมมาก่อนก็สามารถเรียนรู้จากบทความนี้ได้ หวังว่าบทความนี้จะเป็นจุดเริ่มต้นให้คุณได้รู้จักและหลงรัก Python มากขึ้นนะครับ
ในบทความนี้ผมจะอธิบายตั้งแต่การใช้โปรแกรมเขียน Python แล้วใช้ library pandas ในการอ่านข้อมูลจากไฟล์ Excel จากนั้นผมจะใช้ library matplotlib มาสร้างกราฟจากข้อมูล เรียกได้ว่ารวมขั้นตอนการวิเคราะห์ข้อมูลตั้งแต่ต้นจนจบเลยทีเดียว
บทความนี้เป็นบทความจาก Content Creator
เขียนโดย ญาณวุฒิ คิมนารักษ์
บรรณาธิการ ตรวจสอบโดย ศิระ เอกบุตร (เทพเอ็กเซล)
กลั่นมาจากความคิดทั้งสองคน จึงมั่นใจได้ในความถูกต้องมากขึ้นไปอีกครับ
ทำไมต้องใช้ Python
Python เป็นภาษาโปรแกรมที่มีความยืดหยุ่นแลใช้งานได้หลากหลาย เนื่องจากมีเครื่องมือ (library) มากมายที่ช่วยในการวิเคราะห์ข้อมูล เมื่อเปรียบเทียบกับการใช้ spreadsheet เช่น Excel หรือ Google Sheet จุดแข็งของการวิเคราะห์ข้อมูลด้วย Python มีดังนี้
- ปรับแต่งได้ตามต้องการ: Python สร้างกราฟได้หลากลายรูปแบบ ไม่ว่าจะเป็น violin chart, box plot, heat map และยังสามารถปรับแต่งได้แทบทุกอย่างอีกด้วย
- การทำงานกับข้อมูลขนาดใหญ่ (Big data): Python สามารถจัดการกับข้อมูลที่มีขนาดใหญ่และซับซ้อนได้ดีกว่า Spreadsheet ที่มีข้อจำกัดเรื่องจำนวนแถว
- การทำงานแบบอัตโนมัติ: เราสามารถเขียนสคริปต์ให้ Python จัดการข้อมูลแบบอัตโนมัติ ซึ่งจะช่วยลดเวลาและลดความผิดพลาดที่เกิดขึ้นในการประมวลผลข้อมูลด้วยมนุษย์
- การทำ Machine Learning: Python มี library ที่มีประสิทธิภาพสำหรับการทำ Machine Learning โดยเฉพาะ เช่น TensorFlow และ PyTorch
ดังนั้น แม้ว่า Python จะดูน่ากลัวเพราะไม่ได้มีหน้าตาสวยงาม คลิกปุ่มต่าง ๆ ได้เหมือนโปรแกรม spreadsheet และเรายังต้องพิมพ์ตัวอักษรเพื่อสื่อสารกับคอมทำให้ดูใช้งานยาก แต่เมื่อได้รู้จักกันไปเรื่อย ๆ Python ก็เป็นผู้ช่วยที่ดีและตรงไปตรงมาคนหนึ่งเลย
เริ่มต้นเขียนภาษา Python
Python เป็นภาษาคอมพิวเตอร์ที่มีโครงสร้างอ่านง่าย ภาษาคอมมีหลักการเหมือนภาษาในโลกที่เราใช้สื่อสารกัน ถ้าเราพูดภาษาไทยเราก็ต้องพูดกับคนที่เข้าใจภาษาไทยถึงจะสื่อสารกันรู้เรื่องและถ้าเราพูดผิดไวยกรณ์หรือใช้คำผิดก็ทำให้เข้าใจกันคลาดเคลื่อนได้
Python ก็เช่นเดียวกัน เราต้องพิมพ์คำสั่งให้ถูกต้อง ไม่เช่นนั้นผลลัพธ์อาจจะผิด หรือ error ตั้งแต่แรกเลยก็ได้ และเราต้องมีโปรแกรมที่เข้าใจภาษา Python เพื่อให้สื่อสารกับคอมพิวเตอร์ได้
ในบทความนี้ ผมจะใช้ Google colab ในการเขียนภาษา Python โดย Google colab สามารถใช้ฟรีผ่านเวปไซต์เพียงแค่มี gmail และไม่ต้องเสียเวลาติดตั้งโปรแกรมในเครื่องเลยด้วย เจ๋งสุด ๆ
วิธีเข้า Google colab คือไปที่ Google drive login ให้เรียบร้อยแล้วกดเครื่องหมายบวกมุมซ้ายบน จะเห็นตัวเลือกประมาณนี้ให้กดที่ Google Colaboratory

หน้าตา Google colab จะเป็นแบบรูปด้านล่าง เราจะพิมพ์ code ที่กล่องสีเทาแล้วกด run code เพื่อให้ code นั้นทำงานโดยการกดลูกศรซ้ายมือของกล่องที่เราเขียน code ผลลัพธ์จากการ run code จะแสดงด้านล่างกล่องนั้น ถ้าเราต้องการสร้างกล่องเขียน code ใหม่เพื่อเขียน code ชุดต่อไปให้กดที่ปุ่ม +code


Google colb ตอน run ครั้งแรกจะใช้เวลาหน่อย นึกภาพเหมือนเรากำลังไปเชื่อมต่อคอมที่อยู่ที่อื่นครับ หลังจากเชื่อมต่อได้แล้วก็กด run ได้สบาย ๆ เลย
เอาล่ะ! มาเริ่มเขียน code กันเถอะ!
ในบทความนี้ผู้อ่านสามารถลองพิมพ์ code ตามที่บอกแล้วกดปุ่มลูกศรเพื่อ run แล้วดูผลลัพธ์ได้เลย
ก่อนที่จะเริ่มต้นการวิเคราะห์ข้อมูล ต้องทำการติดตั้ง library ที่จำเป็นก่อน library ก็เหมือนเครื่องมือของ Python ที่แต่ละ library ก็เหมาะจะใช้ในงานต่าง ๆ กัน โดยการติดตั้ง library เหมือนการซื้อเครื่องมือมาใส่กระเป๋าให้พร้อมหยิบมาใช้งาน
ในบทความนี้ผมจะใช้ library ชื่อ Pandas และ Matplotlib โชคดีที่ Google colab ติดตั้ง library เหล่านี้ให้แล้ว เราเลยไม่ต้องทำอะไรเพิ่มเติม แต่ถ้ายังไม่ได้ติดตั้ง เราก็สามารถติดตั้งเองได้โดยการ run code นี้
!pip install pandas matplotlibรู้จักกับ Pandas นักจัดการตารางชั้นเยี่ยม
Pandas เป็น library สำหรับการจัดการข้อมูลที่ทรงพลังและใช้งานง่ายใน Python โดย pandas จะเก็บข้อมูลเป็น DataFrame ซึ่งหน้าตาเหมือนตารางใน Excel นั่นแหละ หลังจากนั้นเราก็ใช้ฟังก์ชันต่าง ๆ มาจัดการกับตารางนี้
การเรียกใช้ library (เหมือนหยิบเครื่องมือออกจากกระเป๋ามาเตรียมใช้) จะเริ่มที่การ import ทำได้โดยการ run code นี้ หลังจากนี้เราจะสามารถใช้ library pandas ได้ โดยการพิมพ์ว่า pd (ย่อให้สั้นลงจะได้ไม่ต้องพิมพ์ว่า pandas เต็ม ๆ)
import pandas as pdอ่านข้อมูลจากไฟล์ Excel
เริ่มจากการอัพโหลดข้อมูล Excel ขึ้นไปบน Google colab ก่อน โดยตัวอย่างเป็นข้อมูลการขายของออนไลน์ สามารถดาวน์โหลดชุดข้อมูลได้จาก UCI Machine Learning Repository
วิธีการอัพโหลดไฟล์ทำได้โดยกดที่ปุ่ม Files ด้านซ้ายมือแล้วกดปุ่ม Upload จากนั้นเลือกไฟล์ Excel ที่ดาวน์โหลดลงเครื่องไว้ แล้วกดปุ่ม Open

ถ้าไฟล์ถูก Upload แล้วจะเห็นไฟล์เพิ่มขึ้นมาตามภาพด้านล่าง

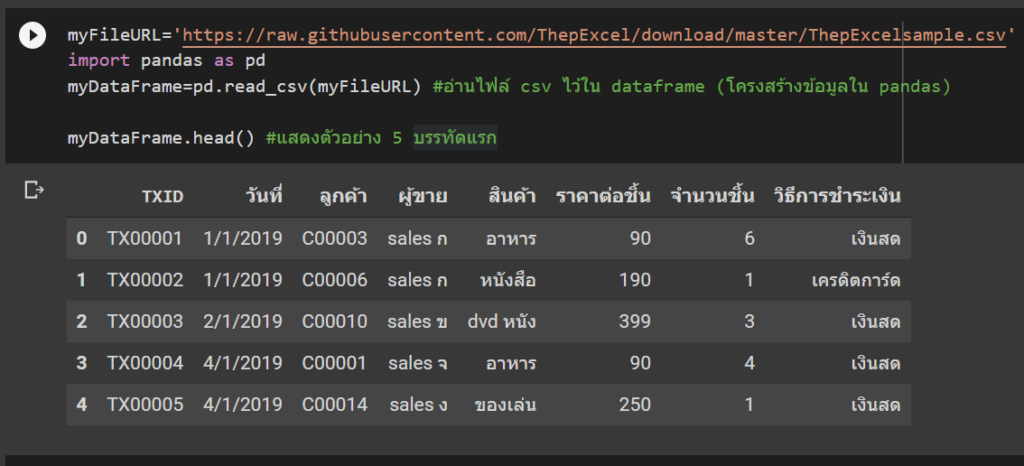
จากนั้นเราจะใช้ pandas ในการอ่านไฟล์ที่อัพโหลดมาแล้วเก็บไว้ในรูปแบบ DataFrame เพื่อใช้งานต่อไป ทำได้โดยการ run code
df = pd.read_excel("Online Retail.xlsx")ในการ run code นี้ไฟล์ Online Retails.xlsx จะถูกเก็บไว้ในตัวแปรชื่อ df
❗ ข้อควรระวังคือ เราจะต้องอัพโหลดไฟล์นี้ใหม่ทุกครั้งที่เราเปิด Google colab อีกครั้ง หรือเมื่อเราปล่อย Google colab ทิ้งไว้นาน จนคอมที่เราไปเชื่อมต่อไว้ดับเอง
อีกวิธีในการอัพโหลดไฟล์จากเวปไซต์ ทำได้โดยให้ Pandas ไปอ่านจากหน้าเวปมาเลย โดยใช้ code นี้
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx'
df = pd.read_excel(url)สำรวจข้อมูล
เมื่อข้อมูลถูกโหลดเข้ามาเก็บเป็น DataFrame แล้ว เราสามารถทำการสำรวจข้อมูลเบื้องต้นเพื่อเข้าใจโครงสร้างและเนื้อหาของข้อมูลได้
– แสดง 5 แถวแรกของข้อมูล (ถ้าอยากแสดงมากกว่า 5 แถวให้ใส่ตัวเลขจำนวนแถวในวงเล็บ เช่น df.head(10) จะแสดง 10 แถวแรก)
df.head()

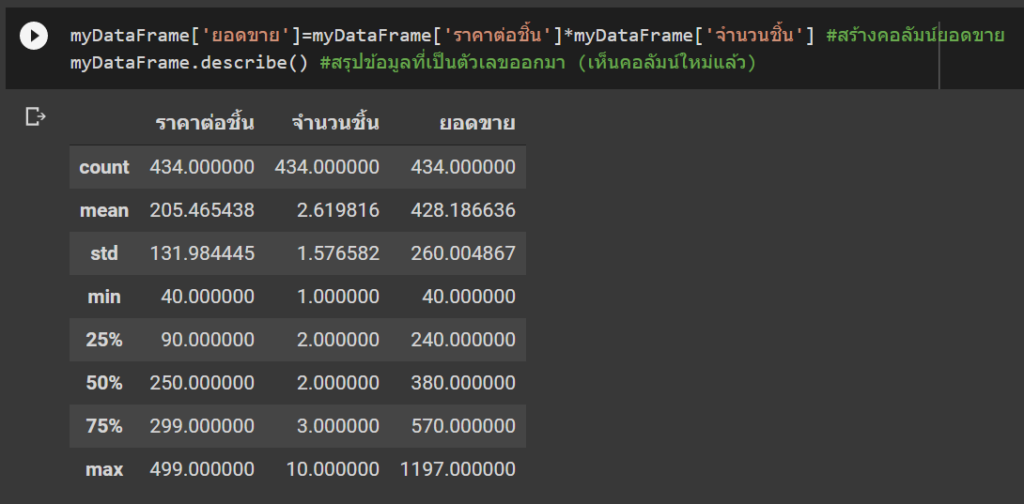
– แสดงสถิติข้อมูลเบื้องต้น เช่น จำนวนแถว, ค่าเฉลี่ย, ค่ามากสุด น้อยสุด, percentile
df.describe()
– แสดงข้อมูลเกี่ยวกับ DataFrame ว่ามีคอลัมน์อะไรบ้าง แต่ละคอลัมน์มีประเภทข้อมูลเป็นอะไร และมีแถวที่เว้นว่าง (null) กี่แถว
df.info()
เลือกข้อมูลบางส่วน
บางทีเราอยากวิเคราะห์แค่บางส่วนของ DataFrame เราสามารถเลือกแค่บางคอลัมน์ หรือบางแถวที่ตรงตามเงื่อนไขที่กำหนดได้
เลือกคอลัมน์
เลือกหนึ่งหรือหลายคอลัมน์จาก DataFrame ทำได้โดยระบุชื่อคอลัมน์ที่อยากจะเรียก ถ้ามีหลายคอลัมน์ต้องซ้อนวงเล็บก้ามปู [] ไปอีกชั้นด้วย
– เลือกคอลัมน์เดียว
df['Country']
– เลือกหลายคอลัมน์
df[['InvoiceDate', 'Country', 'Description']]
เลือกแถว
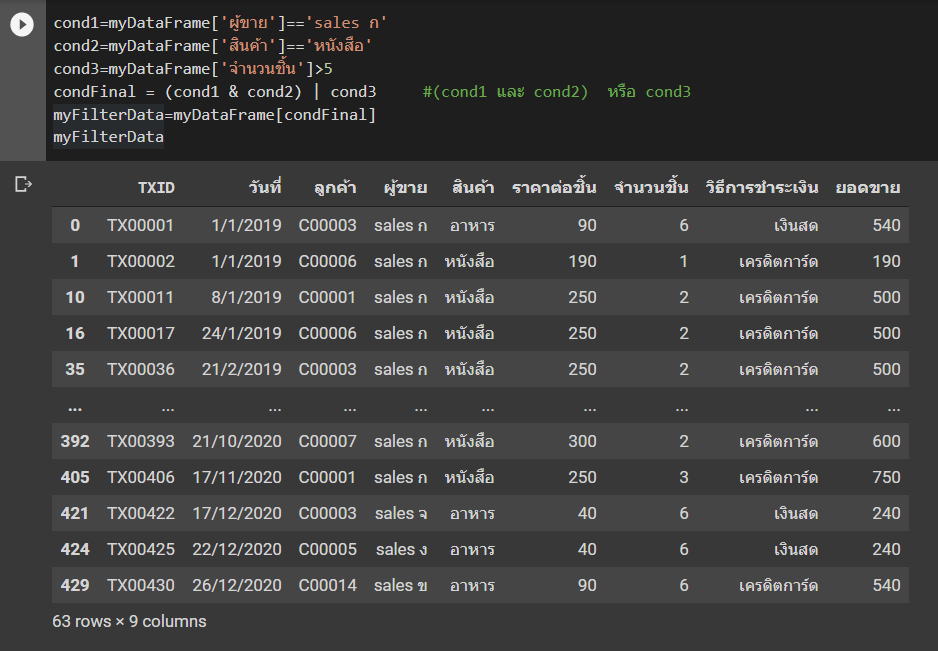
เลือกแถวตามเงื่อนไขที่ต้องการ โดยการระบุคอลัมน์ที่จะใช้ในเงื่อนไขแล้วใส่เครื่องหมายมากกว่า (>) น้อยกว่า (<) เท่ากับ (==) หรือไม่เท่ากับ (!=)
– เลือกแถวที่ปริมาณการขาย (Quantity) มากกว่า 10000
df[df['Quantity'] > 10000]
– เลือกแถวที่ปริมาณการขาย (Quantity) มากกว่า 10000 และราคาต่อชิ้นมากกว่า 1 สังเกตุว่าจะใช้เครื่องหมาย & ในการเชื่อม (ถ้าอยากให้เป็นเงื่อนไข ‘หรือ’ ให้เปลี่ยนเป็นเครื่องหมาย | แทน)
df[(df['Quantity'] > 10000)&(df['UnitPrice'] <= 10)]
นับจำนวน
– จำนวนแถวทั้งหมด ให้เติม .shape[0] ต่อท้าย
df[df['Quantity'] > 10000].shape[0]ได้ผลลัพธ์ว่ามีแถวทั้งหมด 3 แถว หรือก็คือมีการขาย 3 ครั้งที่ตรงเงื่อนไขนี้
– จำนวนข้อมูลที่ไม่ซ้ำกัน ให้เติม .nunique() ต่อท้าย
df['Country'].nunique()ได้ผลลัพธ์ว่าข้อมูลชุดนี้มี 38 ประเทศที่ต่างกัน
– จำนวนแถวของข้อมูลแต่ละชนิด
df['Country'].value_counts()
การจัดการข้อมูล
Pandas ช่วยให้การจัดการข้อมูลทำได้ง่ายมาก เราสามารถนำคอลัมน์มาบวก ลบ คูณ หาร ตัวเลข หรือนำ 2 คอลัมน์มากระทำกันได้ด้วย
เพิ่มคอลัมน์ใหม่
เพิ่มคอลัมน์ใหม่สำหรับยอดขายรวมโดยตั้งชื่อคอลัมน์นี้ว่า Total Sales และคำนวณจากการนำคอลัมน์ Quantity (ปริมาณ) คูณกับ UnitPrice (ราคาต่อหน่วย)
df['Total Sales'] = df['Quantity'] * df['UnitPrice']
df.head()
แก้ไขคอลัมน์
เราสามารถนำเลขมาบวก ลบ คูณ หาร หรือใช้ฟังก์ชันซับซ้อนกับคอลัมน์ได้
เช่น เราต้องการคอลัมน์ที่แสดงราคาส่วนลด 10% จากราคาเดิม เราทำได้โดยสร้างคอลัมน์ใหม่ชื่อ Discounted Price โดยคำนวณมาจากการนำ 0.9 คูณกับคอลัมน์ UnitPrice
df['Discounted Price'] = df['UnitPrice'] * 0.9
print(df[['UnitPrice','Discounted Price']])
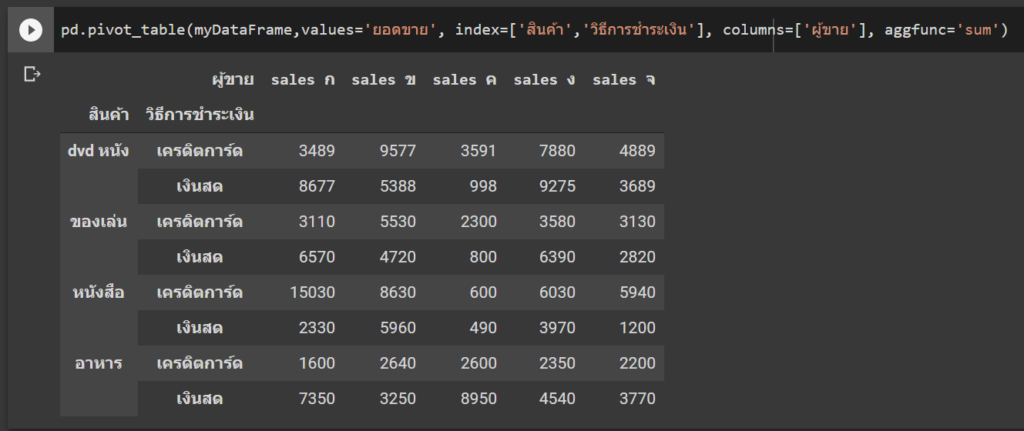
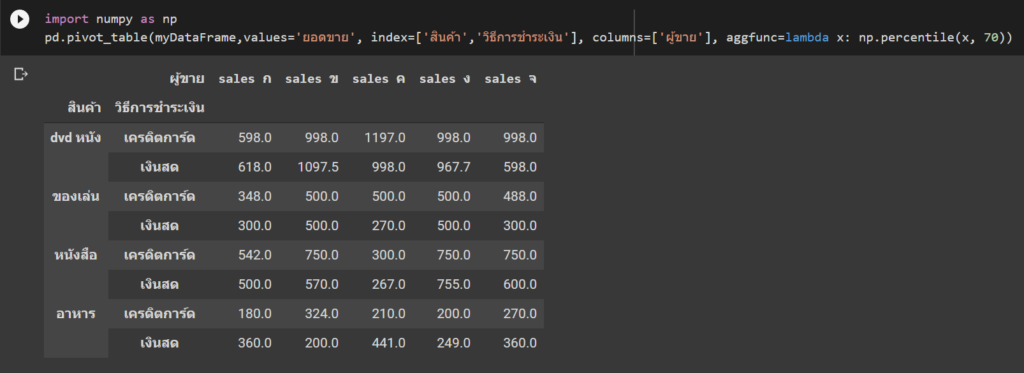
การจัดกลุ่มข้อมูล
การจัดกลุ่มข้อมูลใช้เพื่อแบ่งข้อมูลเป็นกลุ่มก่อนที่จะคำนวณค่าทางสถิติของแต่ละกลุ่ม เช่น ค่าฉลี่ย, ค่าสูงสุด ตัวอย่างเช่น เมื่อเราอยากรู้ยอดขายรวมของแต่ละประเทศ เราทำได้โดยใช้ groupby
sales_per_country = df.groupby('Country')['Total Sales'].sum()
print(sales_per_country)
Groupby สำหรับผู้เริ่มต้นอาจดูเข้าใจยากสักหน่อย ให้ลองมองภาพคล้ายการทำ Pivot table ครับ เวลาอ่าน code อ่านเรียงจากซ้ายไปขวาได้เลย ถ้าเราอยากแบ่งกลุ่มด้วยคอลัมน์อื่นให้เปลี่ยนตรง Country ถ้าอยากคำนวณจากคอลัมน์อื่นก็เปลี่ยนตรง Total Sales หรือถ้าไม่อยากหาผลรวมแต่อยากหาค่าเฉลี่ยก็เปลี่ยนจาก sum เป็น mean ได้เช่นกัน

นอกเหนือจากการใช้ pandas ตามที่ผมเขียนมาในบทความนี้แล้ว pandas ยังมีความสามารถอื่น ๆ อีกมากมาย เรียกได้ว่าเป็นเครื่องมือสารพัดประโยชน์เลยทีเดียว ถ้าอยากรู้จัก pandas มากขึ้นสามารถไปศึกษาเพิ่มเติมที่เวปไซต์ทางการของ pandas กันได้
รู้จักกับ Matplotlib นักสร้างสรรค์กราฟ
Matplotlib เป็น library สำหรับการสร้างกราฟที่ครอบคลุมกราฟหลายแบบมาก ไปดูตัวอย่างได้ที่เวปไซต์ของ matplotlib
เช่นเดียวกับ pandas ก่อนจะใช้ matplotlib เราต้องทำการ import ก่อน โดยเราจะย่อ matplotlib ว่า plt เวลาเรียกใช้
import matplotlib.pyplot as pltการสร้างกราฟง่ายๆ
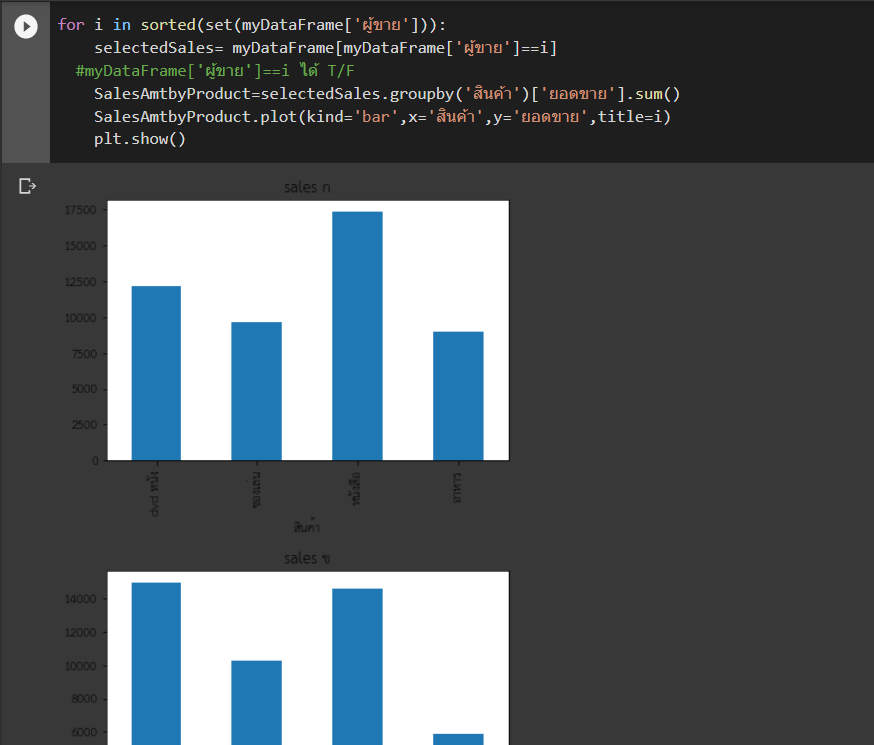
กราฟเส้นแสดงปริมาณการขายแต่ละวัน

วิธีการคือ
- เลือกข้อมูลที่จะสร้างกราฟ โดยเลือกเฉพาะปริมาณที่มากกว่า 0 (ข้อมูลมี Quantity น้อยกว่า 0 ด้วยซึ่งน่าจะเป็นข้อมูลที่บันทึกผิด)
df_pos = df[df['Quantity'] > 0]- ใช้คำสั่ง plt.plot(แกน X, แกน Y) เพื่อสร้างกราฟ โดยเราจะเปลี่ยนแกน X เป็นข้อมูลที่เราอยากพล็อตในแนวนอน และเปลี่ยนแกน Y เป็นข้อมูลที่เราอยากพล็อตในแนวตั้ง ตัวอย่างนี้ผมให้แกน X เป็นคอลัมน์ InvoiceDate และแกน Y เป็นคอลัมน์ Quantity
plt.plot(df_pos['InvoiceDate'], df_pos['Quantity'])- เพิ่มรายละเอียดกราฟ เช่นข้อความที่เขียนที่แกน X, Y (xlabel, ylabel) กับชื่อกราฟ (title) แล้วใช้คำสั่ง plt.show() เพื่อให้กราฟแสดงออกมา
plt.xlabel('Invoice Date')
plt.ylabel('Quantity')
plt.title('Line Plot of Quantity Over Time')
plt.show()การปรับแต่งกราฟ
นอกจากนี้เรายังปรับแต่งกราฟได้อีกมากมายเท่าที่เราจะจินตนาการได้

ปรับขนาดกราฟด้วย plt.figure(figsize = (ความยาวแกน X, ความยาวแกน Y))
ใน plt.plot ใส่รายละเอียดเช่น ความเข้มของสี (alpha), ลักษณะเส้น (linestyle), สีเส้น (color), ความหนาของเส้น (linewidth)
ปรับขนาดตัวอักษรโดยการกำหนด fontsize
แสดงเส้นตารางโดยใช้คำสั่ง plt.grid(True)
หมุนตัวเลขแกน X 45 องศาเพื่อให้อ่านง่ายขึ้นด้วย plt.xticks(rotation=45)
เมื่อเขียนการปรับแต่งทั้งหมดรวมกันจะได้ code ตามด้านล่างนี้
plt.figure(figsize=(10, 6))
plt.plot(df_pos['InvoiceDate'], df_pos['Quantity'], alpha=0.7, linestyle='-', color='green', linewidth=1)
plt.xlabel('Invoice Date', fontsize=14)
plt.ylabel('Quantity', fontsize=14)
plt.title('Line Plot of Positive Quantity Over Time', fontsize=16)
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()การรวม Pandas และ Matplotlib
การรวมความสามารถในการจัดการข้อมูลของ Pandas กับการสร้างกราฟของ Matplotlib ทำให้เราสามารถทำการวิเคราะห์ข้อมูลที่ซับซ้อนและสร้างกราฟที่ตอบโจทย์ธุรกิจได้
ตัวอย่าง: การวิเคราะห์และสร้างกราฟยอดขายรวมแต่ละเดือน
ในตัวอย่างนี้ ผมจะนำสิ่งที่อธิบายไว้ด้านบนมาประกอบกันเพื่อให้เห็นว่าในการใช้งานจริง เราทำอย่างไรบ้าง
# เรียกว่าการ comment โดยข้อความหลังเครื่องหมายจะไม่ถูกอ่านโดยโปรแกรม เราจะทำไว้เพื่อให้มนุษย์เราเข้าใจว่า code ที่เขียนแปลว่าอะไร
โหลดข้อมูล:
import pandas as pd
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx'
df = pd.read_excel(url)การจัดการข้อมูล:
# คำนวณยอดขายรวมโดยเลือกเฉพาะปริมาณที่มากกว่า 0
df_pos = df[df['Quantity'] > 0]
df_pos['Total Sales'] = df_pos['Quantity'] * df_pos['UnitPrice']
# คำนวณยอดขายรวมต่อเดือน
monthly_sales = df_pos.groupby(df_pos['InvoiceDate'].dt.to_period('M'))['Total Sales'].sum()การพล็อตกราฟ:
monthly_sales.plot(kind='line', alpha=0.7, linestyle='--', color='green', linewidth=1)
plt.xlabel('Month', fontsize=14)
plt.ylabel('Total Sales (Million)', fontsize=14)
plt.title('Monthly Sales Over Time', fontsize=16)
plt.grid(True)
plt.show()
จากกราฟนี้เราจะเห็นว่ายอดขายรวมในเดือนพฤศจิกายนสูงที่สุด และยอดขายเดือนกุมภาพันธ์กับเมษายนต่ำกว่าเดือนอื่น ช่วยให้เราวางแผนสต๊อกของได้ ส่วนถ้าเราอยากเพิ่มยอดขาย เราอาจจะลองจัดโปรโมชันในเดือนกุมภาและเมษา โดยอาจวิเคราะห์ให้ลึกขึ้นถึงประเทศที่ยอดขายตกและสินค้าที่ขายดีหรือไม่ดีในแต่ละช่วง แน่นอนว่าใช้แต่ Pandas กับ Matplotlib ก็ทำได้สบาย ๆ
สรุป
ในบทความนี้ ผมได้ครอบคลุมพื้นฐานของการวิเคราะห์ข้อมูลด้วย Python, Pandas และ Matplotlib โดยอธิบายถึงวิธีการสร้างและจัดการข้อมูลด้วย Pandas รวมถึงวิธีการวาดกราฟด้วย Matplotlib แล้วปิดท้ายด้วยการรวมทุกอย่างในโจทย์ตัวอย่างของจริง ความสามารถของ Python ยังมีอีกมากมายที่ยังไม่ได้กล่าวถึงและบทความนี้เป็นเพียงปฐมบทของการวิเคราะห์ข้อมูลด้วย Python เท่านั้น
การฝึกฝนและการเรียนรู้เป็นกุญแจสำคัญในการเชี่ยวชาญการวิเคราะห์ข้อมูล การทำงานกับชุดข้อมูลจริง ลองวิเคราะห์มุมมองต่าง ๆ และสร้างกราฟที่หลากหลาย ช่วยให้เข้าใจข้อมูลและการนำไปใช้ได้ลึกซึ้งยิ่งขึ้น มาสนุกกับ coding กันครับ!